R语言学习 构建Jupyter Lab工作环境与类别型数据处理在在线业务中的应用
R语言作为统计分析和数据可视化的重要工具,在数据科学领域应用广泛。结合Jupyter Lab这一交互式开发环境,用户能更高效地进行数据探索和建模。本文首先介绍如何在Jupyter Lab中配置R工作环境,接着总结类别型数据的处理方法,最后探讨其在在线数据处理与交易处理业务中的实践应用。
一、Jupyter Lab中构建R工作环境
在Jupyter Lab中使用R语言,需先安装R语言环境及IRkernel包。步骤如下:
- 安装R语言:从CRAN官网下载并安装R。
- 安装IRkernel:在R控制台中运行
install.packages('IRkernel'),然后执行IRkernel::installspec()注册内核。 - 配置Jupyter Lab:确保已安装Jupyter Lab,启动后即可选择R内核创建笔记本。这一环境支持代码执行、Markdown文档编写和实时可视化,便于数据分析和结果分享。
二、类别型数据处理方法总结
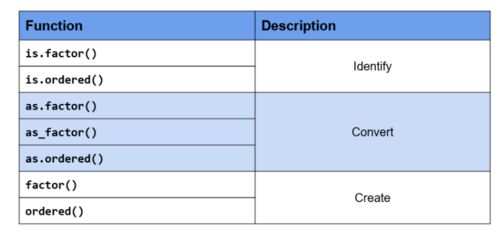
类别型数据(如性别、产品类别)在R中通常以因子(factor)形式处理,关键操作包括:
1. 创建与转换:使用factor()函数将字符向量转换为因子,可指定水平(levels)和标签(labels)。
2. 重编码:通过recode()或ifelse()函数合并或修改类别,例如将多个类别归并为更广泛的组。
3. 哑变量生成:使用model.matrix()或dummyVars包创建哑变量,便于机器学习模型处理。
4. 排序与汇总:利用table()和summary()函数进行频数统计,或使用dplyr包中的group_by()和summarise()进行分组分析。
处理时需注意缺失值处理和类别不平衡问题,以确保数据质量。
三、在线数据处理与交易处理业务中的应用
在在线业务场景中,如电商交易或金融平台,R语言结合Jupyter Lab可用于实时数据分析和决策支持:
1. 实时数据流处理:通过R包如shiny构建交互式仪表板,监控交易数据流并可视化关键指标(如销售额、用户行为)。
2. 类别型数据应用:例如,在用户画像分析中,处理用户性别、地区等类别变量,以进行细分市场推荐;在交易欺诈检测中,将交易类型作为因子输入模型,提高预测准确率。
3. 自动化报告:利用Jupyter Lab的笔记本功能,结合R脚本自动生成交易报告,支持业务决策。
构建高效的R工作环境并掌握类别型数据处理技巧,能显著提升在线业务的处理效率和洞察力,推动数据驱动决策。
如若转载,请注明出处:http://www.xfyaaa.com/product/25.html
更新时间:2025-11-28 14:06:09